之前用的阿谁体例需要计算sign,虽说网上算法已经烂大街了,但是加密用的key不是良多,并且我用的key是在git上偷的,所以就不发阿谁脚本了,发本身弄的一个。
筹办:chrome, chromedriver, selenium(python3),之前的阿谁多线程下载器
链接:ChromeDriver Mirror 找对应版本:chromedriver与chrome各版本及下载地址 - CSDN博客 多线程下载器:【没卵用】多线程下载器
下载好之后,把全数文件放在统一个文件夹内,然后就行了。
源码:
# coding:utf-8 from urllib import request import re from selenium import webdriver import json from selenium.webdriver.common.desired_capabilities import DesiredCapabilities import io import gzip import down import os import time def dezip(source, *, codeform="utf-8"): if source.getheader("Content-Encoding") == "gzip": tmp = io.BytesIO(source.read()) dataunique = gzip.GzipFile(fileobj=tmp).read().decode(codeform) else: dataunique = source.read().decode(codeform) return dataunique file = "E:\\test\\chrome\\" filetmp = file + "tmp\\" try: os.mkdir(filetmp) except FileExistsError: pass header = { "Connection": "keep-alive", "Accept": "application/json, text/javascript, */*; q=0.01", "Origin": "https://www.bilibili.com", "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome" + "/63.0.3239.132 Safari/537.36", "Referer": "https://www.bilibili.com/video/av18420095/?spm_id_from=333.334.chief_recommend.22", "Accept-Encoding": "gzip, deflate, br", "Accept-Language": "zh-CN,zh;q=0.9" } url = "" d = DesiredCapabilities.CHROME d[loggingPrefs] = {performance: ALL} sources = input("input video url or av number:") driver = webdriver.Chrome(".\\chromedriver.exe", desired_capabilities=d) if sources.isdigit(): sourceurl = "https://www.bilibili.com/video/av" + sources else: sourceurl = sources driver.get(sourceurl) # 若是获取不到链接,请翻开sleep(2) # time.sleep(2) for entry in driver.get_log(performance): try: a = re.findall("sign=", str(entry))[1] url = json.loads(entry["message"])["message"]["params"]["response"]["url"] break except IndexError: continue title = driver.title.replace(" ", "").replace("\n", "").replace(".", "") driver.close() if url == "": print("wrong source url") raise RuntimeError print("get url successfully") req = request.Request(url=url, headers=header) data = dezip(request.urlopen(req)) print("get real url successfully") data = json.loads(data) history = open(filetmp + "data.txt", "w") if len(data["durl"]) > 1: for i in data["durl"]: down.download(i["url"], filetmp, str(i["order"]) + ".flv", header=header) history.write("file {0}{1}.flv\n".format(filetmp, str(i["order"]))) history.close() if len(data["durl"]) > 1: os.system("ffmpeg -f concat -safe 0 -i {0} -c copy {1}.flv".format(filetmp + "data.txt", file + title)) for i in os.listdir(filetmp): os.remove(filetmp + i) os.removedirs(filetmp) else: down.download(data["durl"][0]["url"], file, title + ".flv", header=header)食用办法:
av号:
 输入av号
输入av号链接体例:
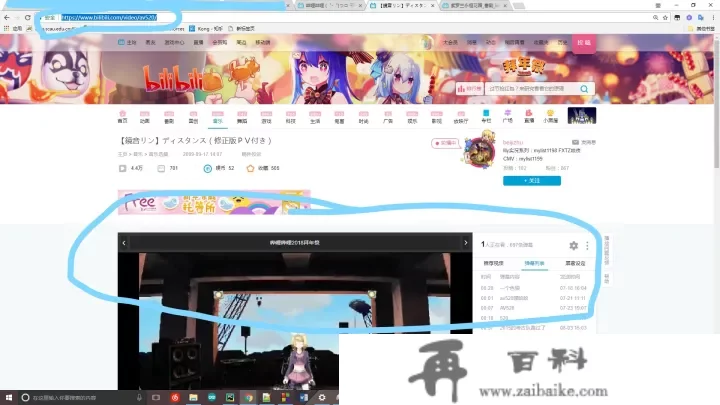 留意是在播放界面
留意是在播放界面
长处:管他喵的加密体例,归正不消用到;适用于所有哔哩哔哩视频(包罗番剧,利用链接体例);
bug:多p视频只下载1p
0