布景
Redis混合存储产物
是阿里云自主研发的完全兼容Redis协议和特征的混合存储产物。
通过将部门冷数据存储到磁盘,在包管绝大部门拜候性能不下降的根底上,大大降低了用户成本并打破了内存对Redis单实例数据量的限造。
此中,对冷热数据的识别和交换是混合存储产物性能的关键因素。 冷热数据定义在Redis混合存储中,内存和磁盘的比例是用户能够自在选择的:
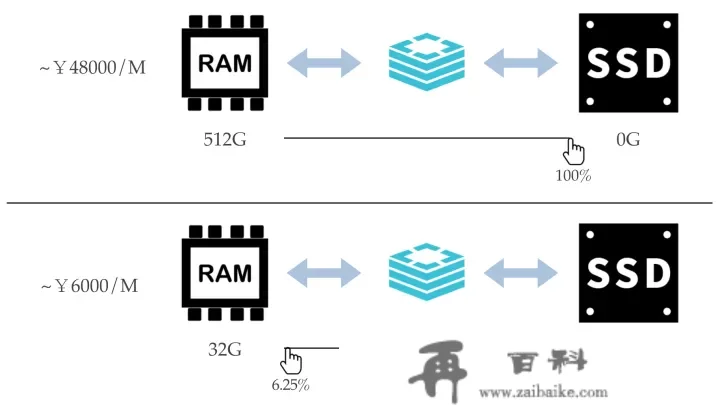
Redis混合存储实例将所有的Key都认为是热数据,以少量的内存为代价包管所有Key的拜候恳求的性能是高效且一致的。而关于Value部门,在内存不敷的情况下,实例自己会按照比来拜候时间,拜候频度,Value大小等维度拔取出部门value做为冷数据后台异步存储到磁盘上曲到内存小于造定阈值为行。
在Redis混合存储实例中,我们将所有的Key都认为是热数据保留在内存中是出于以下两点考虑:
Key的拜候频度比Value要高良多。
做为KV数据库,凡是的拜候恳求都需要先查找Key确认Key能否存在,而要确认一个key不存在,就需要以某种形式查抄所有Key的集合。在内存中保留所有Key,能够包管key的查找速度与纯内存版完全一致。Key的大小占比很低。
即便是通俗字符串类型,凡是的营业模子里面Value比Key要大几倍。而关于Set,List,Hash等集合对象,所有成员加起来构成的Value更是比Key大了好几个数量级。因而,Redis混合存储实例的适用场景次要有以下两种:
数据拜候不平均,存在热点数据;内存不敷以放下所有数据,且Value较大(相关于Key而言)冷热数据识别当内存不敷时的情况下,实例会根据比来拜候时间,拜候频度,value大小等维度计算出value的权重,将权重更低的value存储到磁盘上并从内存中删除。
伪代码如下: while used_memory > max_memory coldest_value = pick_coldest_value() swap_value(coldest_value)end抱负的情况下,我们当然希望可以准确的计算出当前最冷的value。然而,value的冷热水平按照拜候情况动态变革的,每次都从头计算所有value的冷热权重的时间消耗是完全不成承受的。
Redis自己在内存满的情况下会按照用户设置的裁减战略裁减数据,而热数据从内存写到磁盘也能够认为是一种“裁减”的过程。从性能,准确率以及用户理解水平考虑,我们在冷热数据识别时接纳和Redis类似的近似计算办法,撑持多种战略, 通过随机采样小部门数据来降低CPU和内存消耗,通过eviction pool操纵采样汗青信息来辅助进步准确率。

上图为差别版本和差别采样样本数目设置装备摆设下,Redis近似裁减算法的射中率示企图。浅灰色的点为被裁减数据,灰色的点为未裁减数据,绿色点为测试过程中新参加的数据。
冷热数据交换Redis混合存储在冷热数据交换过程在后台IO线程中完成。
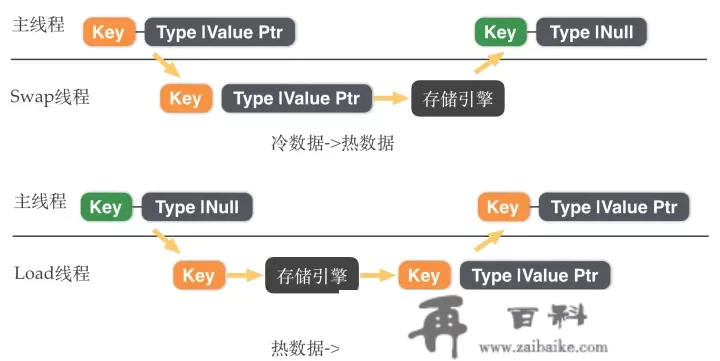 热数据->冷数据
热数据->冷数据
异步体例:
主线程在内存接近更大值时,生成一系列数据换出使命;后台线程施行那些数据换出使命,施行完毕之后通知主线程;主线程更新释放内存中的value,更新内存中数据字典中的value为一个简单的元信息;
同步体例:若是写入流量过大,异步体例来不及换出数据,招致内存超出更大规格内存。主线程将间接施行数据换出使命,到达变相限流的目标。
冷数据->热数据异步体例:
主线程在施行号令前,先判毕命令涉及的value能否都在内存中;若是不是,生成数据加载使命,挂起该客户端,主线程继续处置其他客户端恳求;后台线程施行数据加载使命,施行完毕后通知主线程;主线程在内存中更新数据字典中的value,唤醒之前挂起的客户端,处置其恳求。
同步体例:在Lua脚本,详细号令施行阶段,若是发现有value存储在磁盘上,主线程将间接施行数据加载使命,包管Lua脚本和号令的语义稳定。
本文做者:怀听
原文链接
更多手艺干货敬请存眷云栖社区知乎机构号:阿里如此栖社区 - 知乎
本文为云栖社区原创内容,未经允许不得转载。